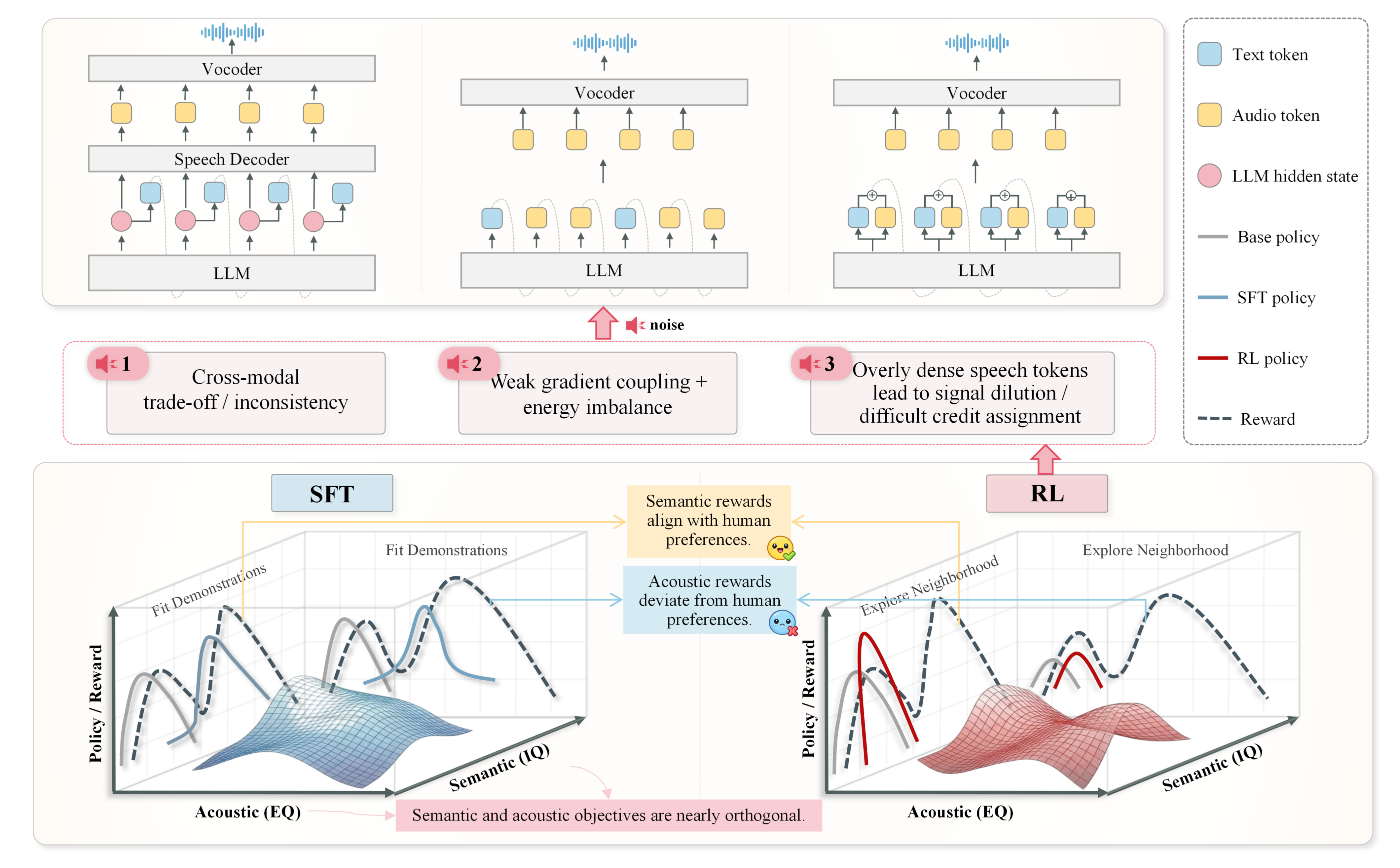
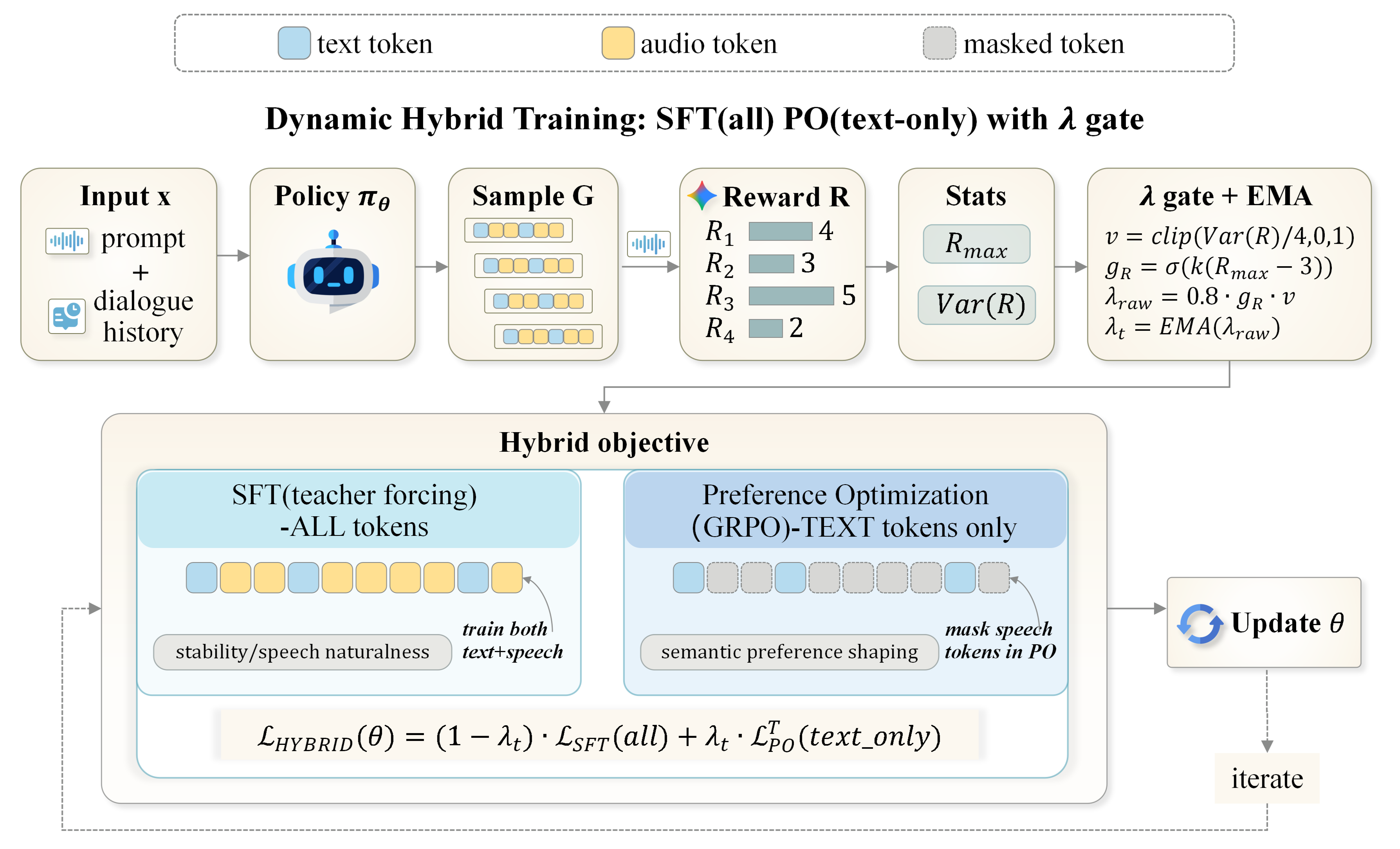
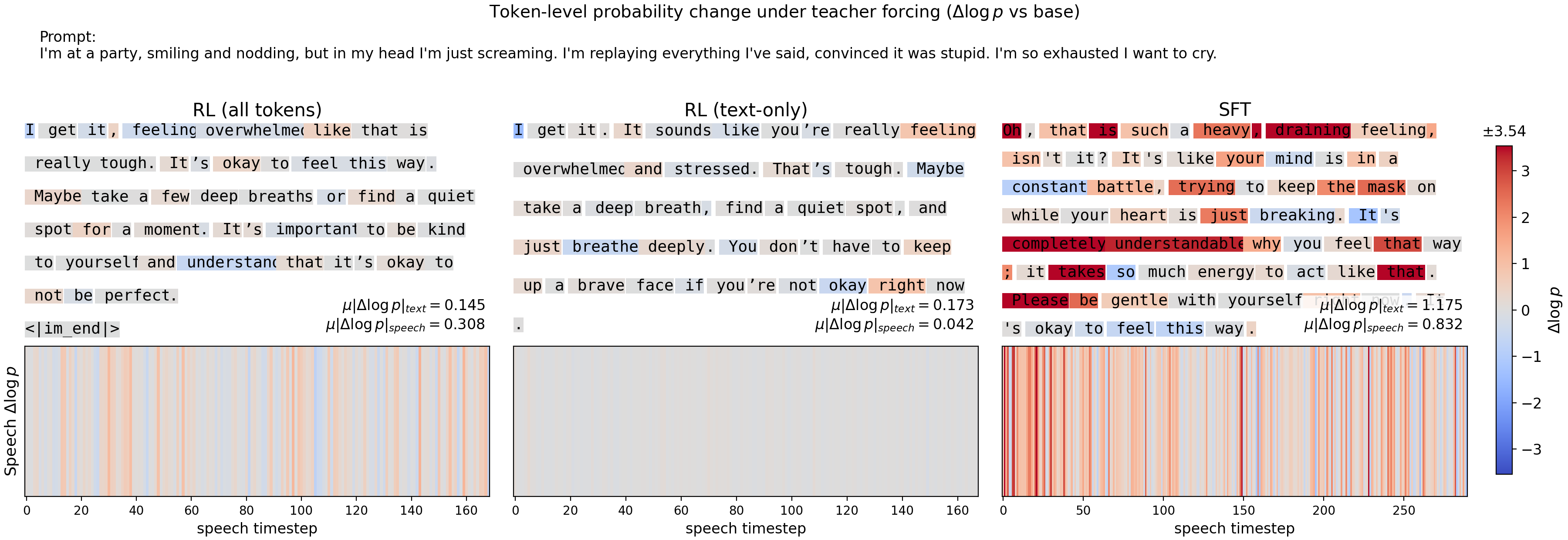
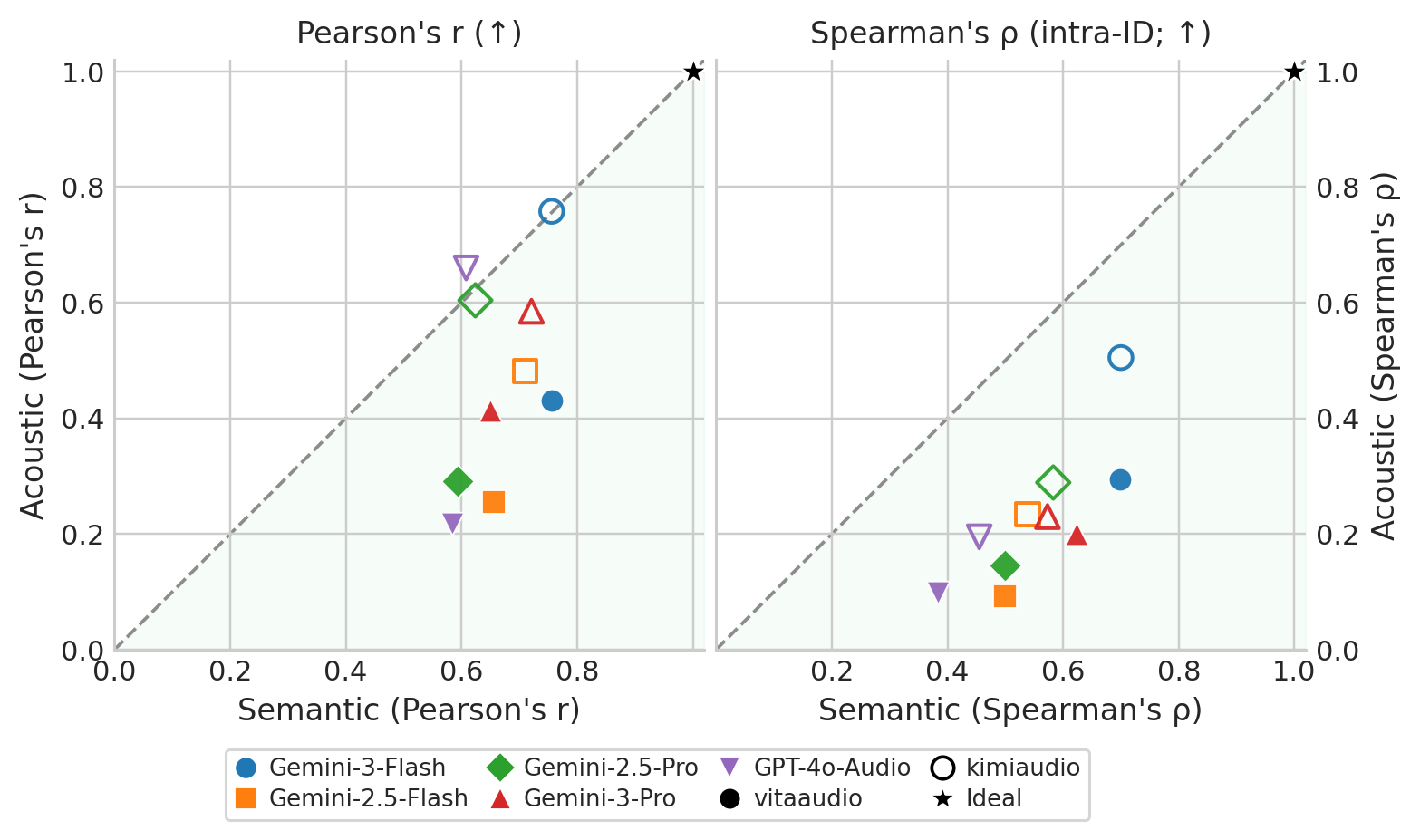
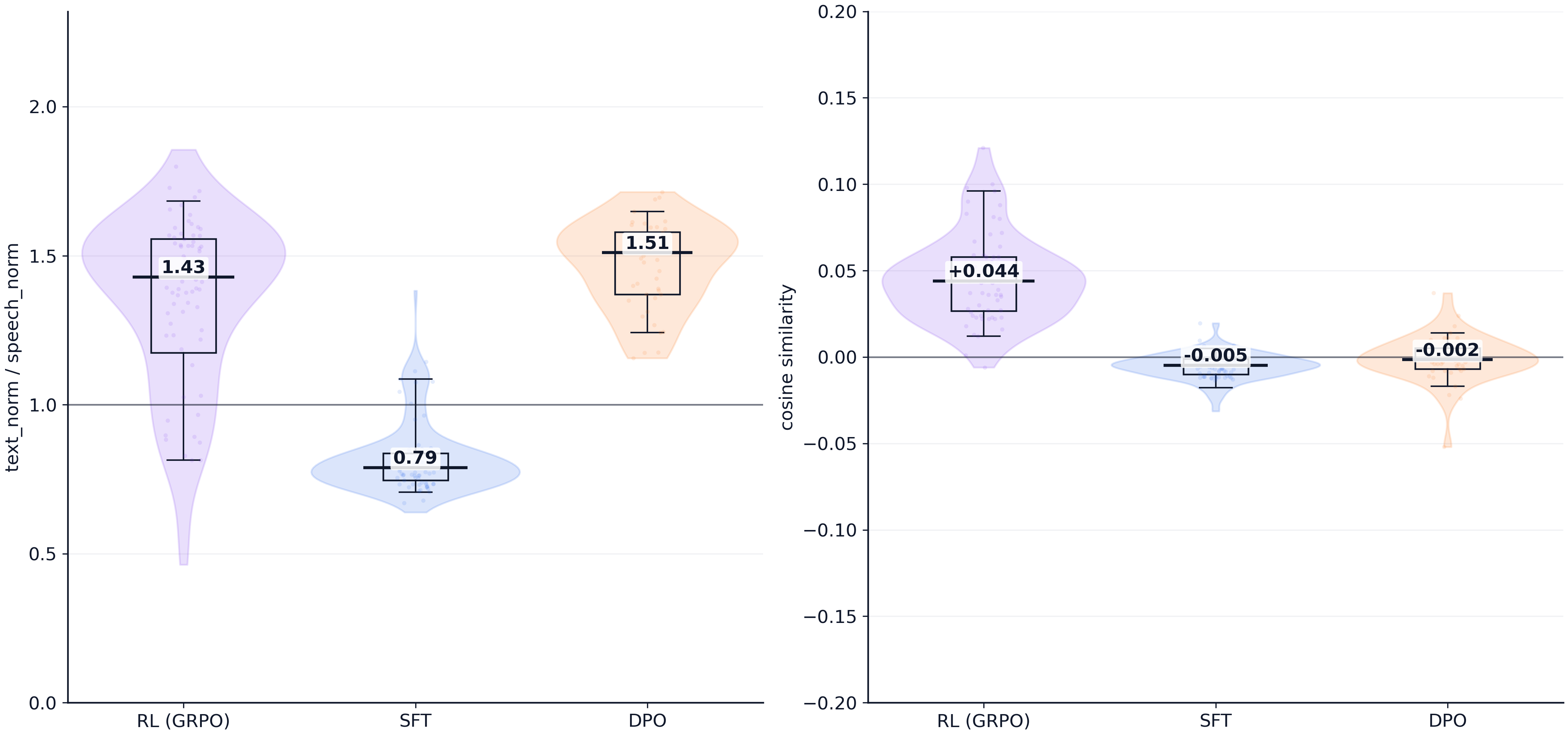
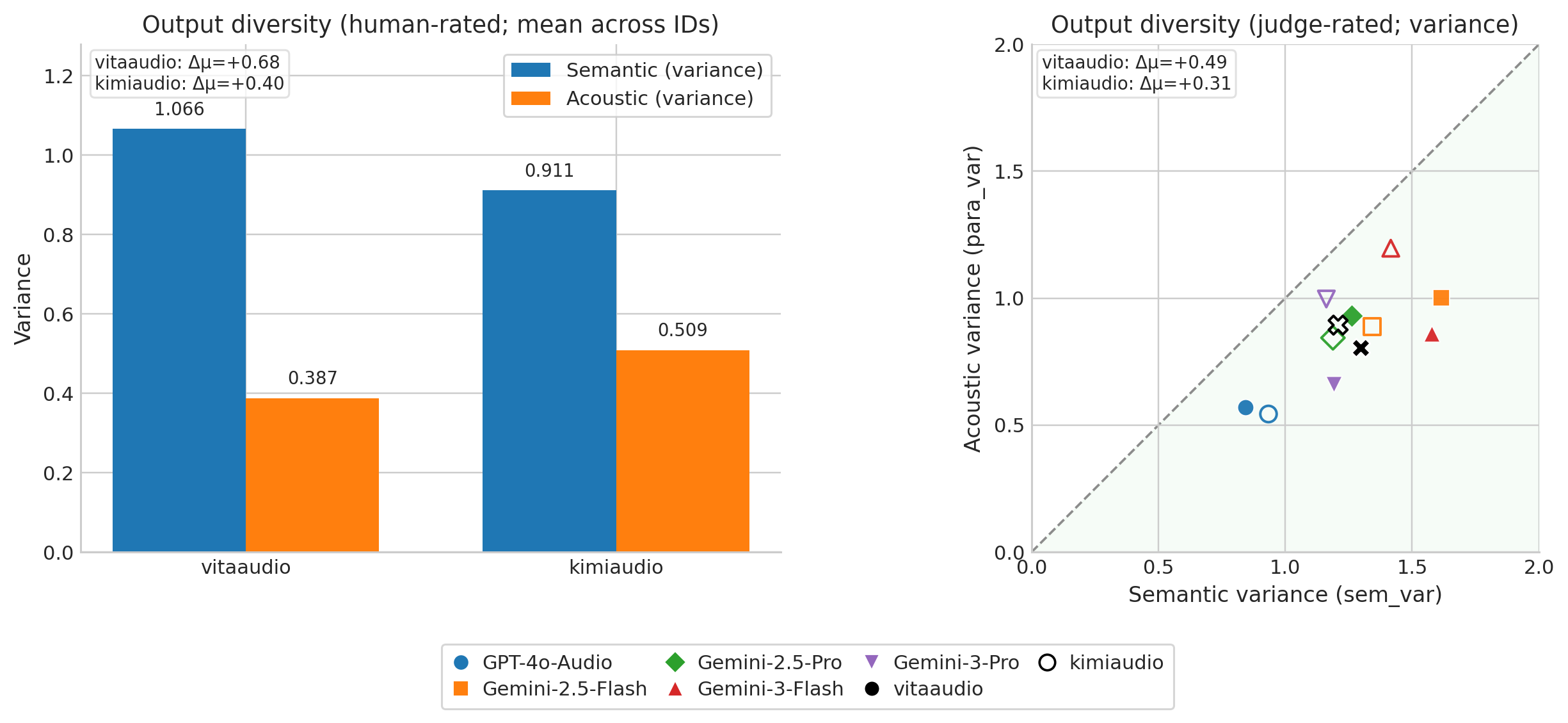
Our dynamic hybrid method achieves the strongest overall IQ among all compared methods across both VITA (interleaved) and KimiAudio (parallel) architectures. Restricting preference updates to text tokens yields more reliable IQ gains than full-token optimization.
| Method | VoiceBench | OpenAudioBench | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Alpaca | Common | Wild | SD-QA | MMSU | OBQA | BBH | IFEval | Adv | Alpaca | Llama | Reason | Trivial | Web | |
| VITA Architecture (Interleaved) | ||||||||||||||
| VITA-Base | 3.83 | 3.44 | 3.09 | 29.2 | 48.7 | 74.3 | 58.2 | 26.2 | 94.1 | 60.6 | 73.8 | 44.2 | 42.9 | 53.5 |
| SFT | 3.45 | 3.12 | 2.85 | 27.6 | 45.1 | 71.5 | 54.9 | 28.4 | 99.2 | 55.6 | 71.1 | 38.4 | 39.9 | 48.3 |
| Full-Token DPO | 3.60 | 3.29 | 2.89 | 30.2 | 44.7 | 69.2 | 56.8 | 22.6 | 65.0 | 20.1 | 55.4 | 33.4 | 29.8 | 36.6 |
| Text-Token DPO | 3.91 | 3.32 | 3.13 | 31.1 | 45.6 | 69.7 | 60.3 | 32.8 | 71.3 | 57.2 | 74.3 | 43.1 | 43.1 | 54.3 |
| Full-Token RL | 4.03 | 3.45 | 3.19 | 29.9 | 49.0 | 74.1 | 55.6 | 29.4 | 96.3 | 63.8 | 73.3 | 43.7 | 43.3 | 52.8 |
| Text-Token RL | 4.09 | 3.44 | 3.20 | 31.3 | 50.0 | 75.4 | 56.7 | 30.2 | 96.3 | 64.6 | 74.6 | 44.4 | 44.4 | 53.2 |
| SFT + RL (Two-Stage) | 3.49 | 3.32 | 2.69 | 22.5 | 44.7 | 70.8 | 54.2 | 25.5 | 98.8 | 54.0 | 66.2 | 32.8 | 35.1 | 49.0 |
| Ours (Dynamic) | 4.22 | 3.51 | 3.29 | 31.5 | 51.4 | 77.1 | 59.9 | 32.5 | 97.1 | 68.4 | 74.6 | 46.1 | 44.4 | 54.7 |
| KimiAudio Architecture (Parallel) | ||||||||||||||
| KimiAudio-Base | 4.46 | 3.97 | 3.42 | 63.1 | 62.2 | 83.5 | 64.2 | 61.1 | 100.0 | 75.7 | 79.3 | 58.0 | 62.1 | 70.2 |
| SFT | 4.15 | 3.65 | 3.10 | 59.8 | 58.4 | 79.5 | 61.2 | 64.5 | 100.0 | 71.4 | 75.2 | 52.8 | 58.4 | 66.9 |
| Full-Token DPO | 4.05 | 3.60 | 3.05 | 58.2 | 55.1 | 76.8 | 59.4 | 58.4 | 88.5 | 68.2 | 70.4 | 50.1 | 55.3 | 65.1 |
| Full-Token RL | 4.52 | 4.05 | 3.50 | 65.2 | 63.8 | 84.6 | 64.8 | 62.8 | 100.0 | 75.8 | 78.5 | 58.8 | 61.2 | 71.5 |
| Ours (Dynamic) | 4.58 | 4.22 | 3.68 | 67.9 | 66.5 | 87.1 | 68.3 | 66.8 | 99.5 | 78.5 | 81.2 | 61.5 | 61.8 | 71.1 |